
AI 캐싱 전략: 느린 AI를 순식간에 빠르게 만드는 비밀 무기 | 매거진에 참여하세요
AI 캐싱 전략: 느린 AI를 순식간에 빠르게 만드는 비밀 무기
#캐싱 #AI서비스 #최적화 #속도 #응답 #비용 #스트리밍 #병렬화 #프롬프트




AI 서비스를 만들다 보면, 한 번쯤 이렇게 외치게 됩니다.
“아니, 또 같은 질문? 매번 5초씩 기다려야 돼?”
맞아요. LLM은 똑똑하지만, 매번 계산하는 데 시간이 걸립니다.
게다가 모델이 크면 클수록, 토큰이 많으면 많을수록, 반복 요청이 많으면 많을수록 속도 문제와 비용 문제가 폭발합니다.
이때 등장하는 비장의 무기 → 캐싱(Caching).
말 그대로 한 번 계산한 결과는 저장하고, 다음엔 바로 꺼내 쓰자 전략입니다.
하지만 그냥 저장만 하면 안 돼요. 제대로 설계하고, 스트리밍, 병렬화, 프롬프트 최적화까지 함께 써야 진짜 속도가 폭발합니다.
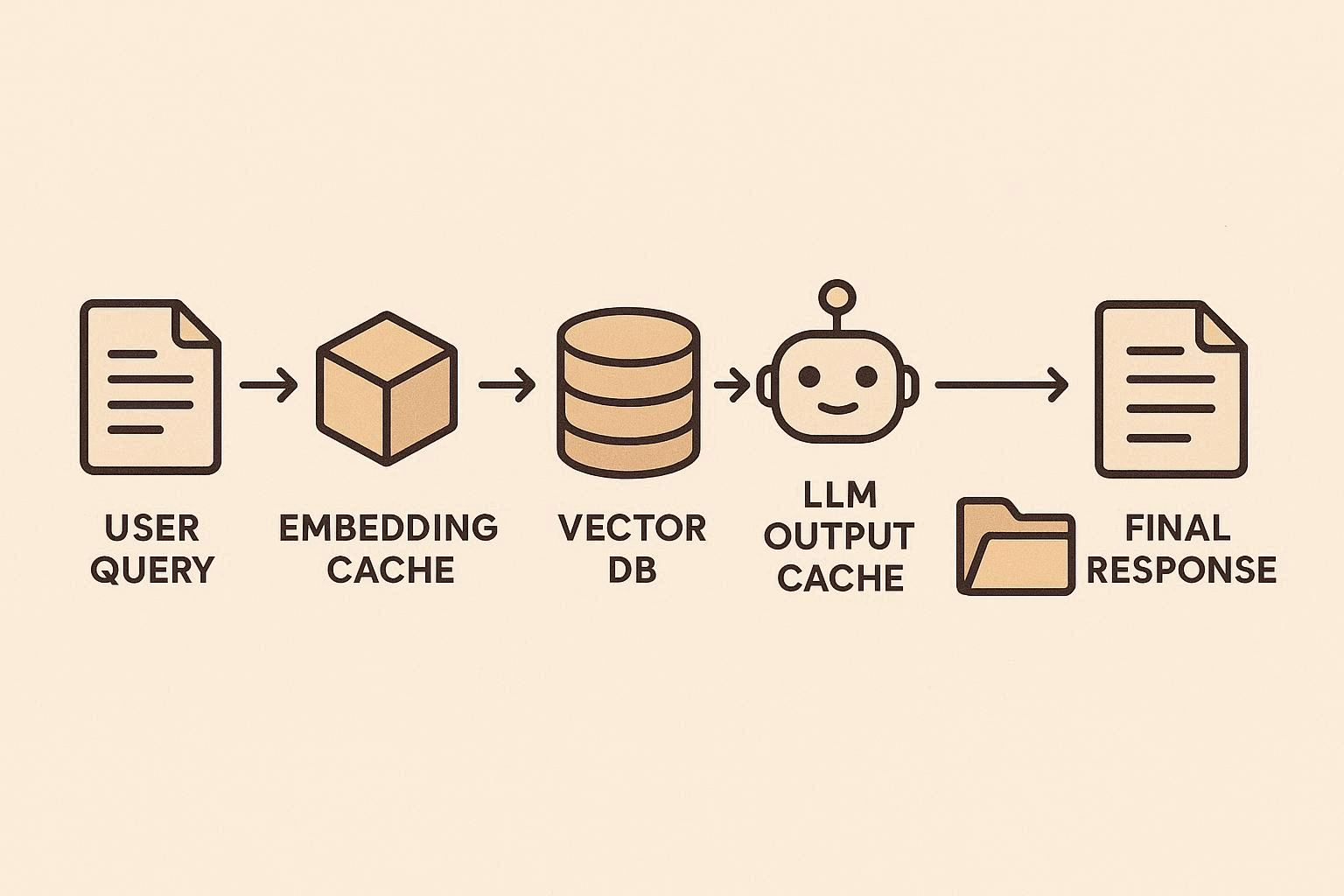
1. 캐싱: 반복 계산 제거
AI 캐싱 전략은 크게 세 가지로 나눌 수 있습니다.
1-1. Embedding 캐싱
Embedding은 텍스트를 벡터로 바꾼 결과입니다.
동일 문서는 항상 같은 벡터 → 반복 계산 불필요 . 특히 RAG(검색 기반 AI)에서 검색 전 단계에서 큰 효과
실제 사례:
50만 문서 chunk를 Vector DB에 넣고, 자주 쓰이는 chunk embedding을 캐시 → Vector DB 호출 40% 감소, latency 50% 감소.
if query_text in embedding_cache:
embedding = embedding_cache[query_text]
else:
embedding = model.embed(query_text)
embedding_cache[query_text] = embedding한 번 계산하고 캐시에 저장 → 다음엔 바로 꺼내 쓰는 구조
1-2. LLM 출력 캐싱
동일 질문 + 프롬프트 → 결과도 항상 동일
FAQ나 반복 질문에서 폭발적 효과
key = hash(prompt_text)
if key in response_cache:
answer = response_cache[key]
else:
answer = model.generate(prompt_text)
response_cache[key] = answer1-3. Chunk/부분 캐싱
문서 전체가 아니라 자주 쓰이는 문서 조각(chunk) 단위 캐싱
RAG 검색 시 이미 검색된 chunk를 재활용 → Vector DB 호출 횟수 감소
비유: 마트에서 통째로 과일 사서 냉장고에 넣고, 매번 필요한 만큼만 꺼내 쓰는 느낌
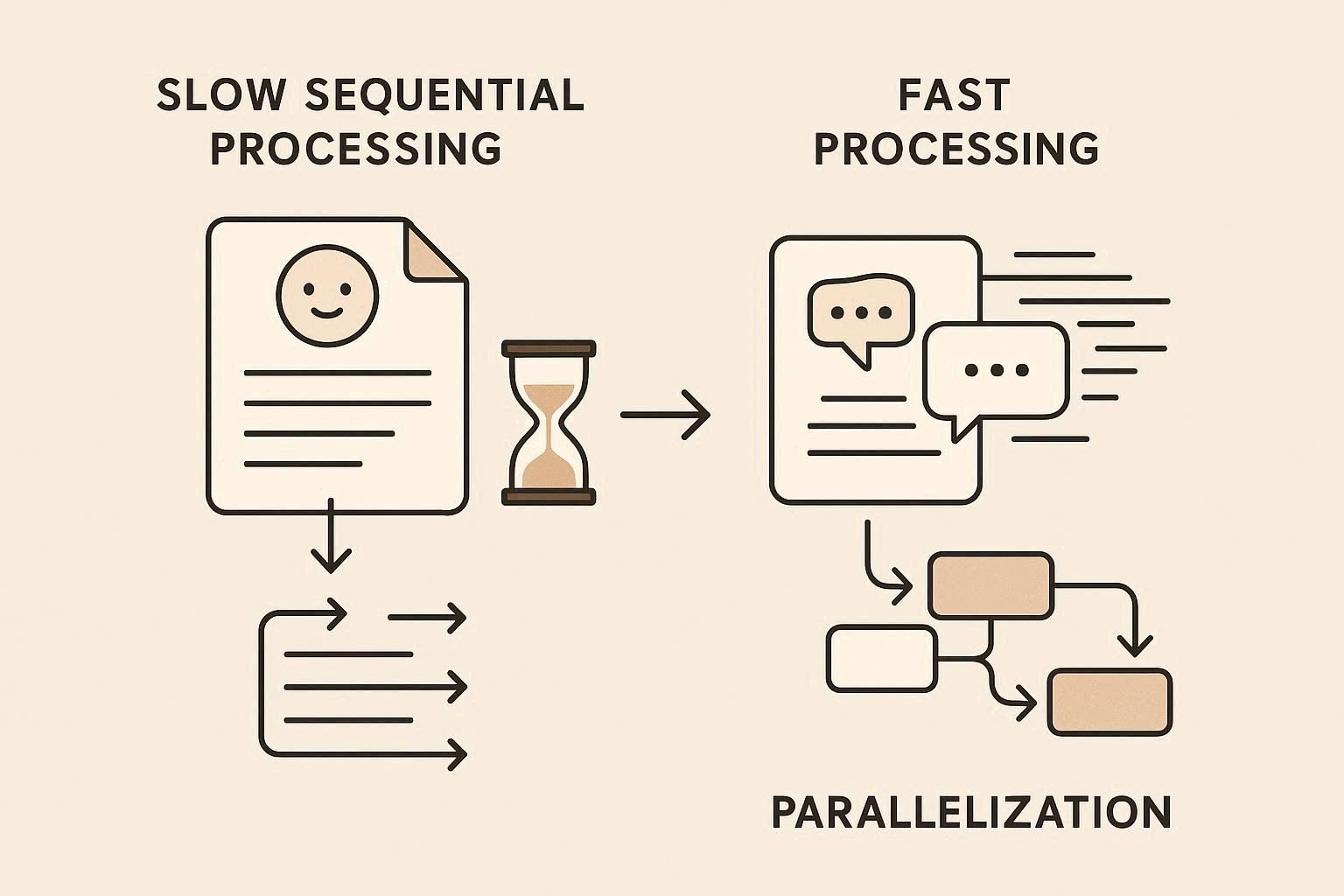
2. 캐싱만으로 충분하지 않을 때: 스트리밍과 병렬화
캐싱만 하면 속도가 빨라지긴 하지만, 사용자가 체감하는 “빠르다!” 느낌을 만들기 위해서는 스트리밍과 병렬화가 필요합니다.
2-1. 스트리밍: 체감 속도 혁명
LLM 출력이 길 때, 한 번에 다 받으면 기다림이 길어짐
토큰 단위로 바로바로 전송 → 사용자는 답변이 거의 실시간으로 나타나는 느낌
for token in model.stream_generate(prompt):
print(token, end="", flush=True)체감: 5초 대기 → 0.5초 느낌
2-2. 병렬화: 동시에 여러 단계 처리
- RAG 기반 검색 + LLM 처리 + 후처리 → 순차로 처리하면 느려집니다.
- 순차 처리: 1초 + 1초 + 1초 = 3초
- 병렬 처리: 동시에 처리 → max(1,1,1) = 1초
실제 적용 사례:
Multi-Agent 시스템에서 Agent가 여러 단계를 동시에 수행 → 처리 시간 2~3배 단축
3. 프롬프트 최적화: 모델 부담 줄이기
캐시 + 스트리밍 + 병렬화와 함께 고려해야 하는 전략: 프롬프트 최적화
필요 없는 정보 제거 → 모델 처리 속도 단축
문서 전체 대신 summary 활용 → 토큰 수 감소
모델 호출 횟수 최소화 → 비용 절감
4. 캐싱 설계 시 주의점
그냥 저장만 하면 문제 발생.
- 오래된 정보 → 잘못된 답변 제공
- 메모리 폭발 → 서버 다운
해결 전략:
- TTL(Time-To-Live)
캐시 데이터 일정 시간 후 갱신
FAQ → 1시간, Embedding → 영속적
- Eviction 정책
용량 제한 시 어떤 데이터를 제거할지 결정
LRU: 가장 오래 안 쓰는 데이터 제거
LFU: 가장 사용 빈도 낮은 데이터 제거
- Key 설계
프롬프트 + 파라미터 + 모델 버전 포함
모델 업데이트 시 구버전 답변 재사용 방지
5. 실제 적용 사례 종합
전략 | 효과 |
|---|---|
Embedding 캐싱 | Vector DB 호출 40% ↓, latency 50% ↓ |
LLM 출력 캐싱 | FAQ 응답 속도 70% ↑, 비용 30% ↓ |
Chunk 캐싱 | RAG 검색 효율 ↑ |
스트리밍 | 체감 대기 시간 90% ↓ |
병렬화 | Multi-Agent 처리 2~3배 빨라짐 |
프롬프트 최적화 | 토큰 수 30~50% ↓, 모델 처리 속도 ↑ |

- link_kakaolink_kakao_url
- link_operatorlink_operator_url
- link_investhelp@letspl.me
- link_ad_urllink_ad
